
Journal of Law, Information and Science

|
|
Home
| Databases
| WorldLII
| Search
| Feedback
Journal of Law, Information and Science |
|
HUI YANG AND MINJIE ZHANG[*]
Agent-based paradigm seems to be a promising technology for developing applications in open, distributed and heterogeneous environments, such as the Internet. Many application areas, such as information retrieval can benefit from the application of agent technology. Despite the advantages offered by agent-based systems, some legal concerns such as liability, security, and privacy protection are raised by intelligent agents. After examining the various kinds of agents, this paper surveys those legal concerns, focusing on issues arising from the applications of agent-based information retrieval on the Internet. Finally, we offer a security framework for our ongoing project – IISS, an agent-based intelligent information selection system for distributed information sources, which makes IISS suitable to build and support legal applications on the Internet.
Keywords: Information Retrieval, Internet, Intelligent Software Agents, Legal Aspects, Privacy, Security, Liability, IRP/Copyright
Due to the explosive growth of the Internet, finding specific information is becoming extremely difficult, sometimes even frustrating for users or machine systems to collect, filter, retrieve, and use in problem solving. The notion of intelligent software agents has emerged to address this challenge.[1] Intelligent software agents are programs that act on behalf of their human users to perform laborious information-gathering tasks. These tasks include:
• Locating and accessing information from various on-line information sources.
• Resolving inconsistencies in the retrieved information.
• Filtering away irrelevant or unwanted information, integrating information from heterogeneous information sources, and adapting over time to the human user’s information needs.
Due to having the abilities of searching, retrieving, filtering and presenting relevant information, reactively and proactively, intelligent software agents offer promising solutions to the current information explosion on the Internet and problems of information retrieval (IR). They have the potential to mitigate the complexity of information retrieval and management by providing a locus of intelligence. Agents could provide intelligent IR interfaces, or perform mediated searching and brokering, clustering and categorization, summarization and presentation. Agent based approaches make IR systems more scalable, flexible, extensible and interoperable.
These intelligent software agents can perform certain tasks on behalf of their user in an autonomous fashion and with some level of pro-activity and/or reactivity. They can also exhibit some level of the key attributes of learning, cooperation and mobility. When these specific features help intelligent agents to act as an assistant to the user in carrying out the task of information retrieval, some legal issues that are raised by use of agents as well as other products and services are beginning to attract attention from various academic disciplines.[2] These include information technology, law, economics, as well as from the business community since it has been recognized that agents will play an important role in E-Commerce and E-business.
This paper deals with some legal facets of intelligent agents used for information retrieval on the Internet. After examining the various kinds of agents (user interface agents, information agents, mediator agents) that can be distinguished in information retrieval and multi-agent systems (MAS) currently widely used on distributed information retrieval on the Internet, we discuss the legal concerns that certain unique characteristics of intelligent agents raise. These issues make agents more susceptible to liability law than conventional software and designers should be wary of them. Finally, we offer a security framework for our ongoing project – IISS, an agent-based intelligent information selection system for distributed information sources to ensure agent integrity. This security framework makes IISS suitable to build and support legal application on the Internet providing efficiency at the same time.
As mentioned previously, intelligent agents have been widely developed for the application on information retrieval on the Internet. For the purpose of this article we will produce a simplified classification according to the features of information retrieval on the Internet. Currently, most agent-oriented approaches focus on the following application:
The major factors that distinguish Adaptive User Interface Agents[3] from any other GUI are the fact that agents are proactive and enjoy a degree of autonomy. Adaptive User Interface Agents can undertake an information-filtering role based upon perceived user interests with limited or no intervention on the part of user. In addition to these general properties it is usual for an interface agent to fulfil at least some of the following roles:
• Reduce the interface complexity and enhance the ease of use in the presence of greater functionality.
• Present the user with an easy to use interface that hides from them the actual underlying system that may be very complex.
• Observe and learn the user’s preferences and habits to attempt to build up a profile of the user. This should be based upon the user's behavior in terms of interactions with the interface and the agent's knowledge of the semantics attached to the individual interface components.
Information agents[4] provide intelligent access to a heterogeneous collection of information sources. Information agents have models of the associated information resources and strategies for source selection, information access, conflict resolution, and information fusion. Briefly an information agent is a program that has the ability to:
• Filter the inexhaustible amount of information available on the Internet, passing on to the user only the information that the user is interested in.
• Communicate with other agents using an agent communication language, e.g. KQML
• Monitoring an information source for a change in a piece of information.
A mediator[5] is a special kind of information agent acting as middleware to take as input, a request to find an agent that provides a service, and returns as output, a list of such agents and their cooperation relationship. Mediator agents support decision-making by formulating problem-solving plans and carrying them out through querying and exchanging information with other software agents. They have strategies for resolving conflicts and fusing information retrieved by information agents. So they exhibit a higher level of sophistication and complexity than either an interface or information agent.
With the emergence of the Internet, there are many, many databases stored in many different locations. Obviously, there is no sense in replicating remote databases permanently at each local site due to space requirements and the cost of transporting it all over the Internet, nor do you want to manually search all information sources through Web sites for a piece of desired information. Therefore, it is natural to adopt a distributed architecture consisting of many software agents specialized for different heterogeneous information sources.
Such multi-agent systems (MAS)[6] can compartmentalize specialized task knowledge and organize themselves to avoid processing bottlenecks. Furthermore, they can be built expressly to deal with dynamic changes in the agents and information sources. In addition, multiple intelligent coordinating agents are ideally suited to the predominant characteristics of the Internet, such as the heterogeneity of the information source, the diversity of information-gathering and problem-solving tasks that the gathered information supports, and the presence of multiple users with related information needs. Therefore, a distributed approach is superior and is possibly the only one that would work for information gathering and coherent information fusion.
As we see it, such multi-agent systems may comprise interface agents tied closed to an individual human’s goals, mediator agents involved in the processes associated with arbitrary problem-solving tasks, and information agents which are closely tied to a source or sources of data.
Intelligent agents are software entities that can perform their tasks on behalf of their user in an autonomous fashion. The size and nature of the legal dimension of the use of intelligent agents for information retrieval are determined by the function of the agents involved and the tasks that are performed. The legality and liability of agents would pose new challenges in developing intelligent information retrieval system on the Internet.
The following paragraph will deal with a number of legal issues that are particularly relevant to the three types of intelligent software agents and multi-agent systems (MAS) used on information retrieval on the Internet.
With the feature of autonomy, agents somewhat control their own actions and do not depend on constant human feedback.[7] The greater the independence of agents the more potential liability issues the development and use of agents gives rise to. With regard to adaptive user interface agents, they automatically customize themselves to the preference of their users on the basis of previous experience and adapt to changes in their environments. However, the dynamic and complex environment in which agents operate makes it impossible to precisely predict the adaptive learning behavior of user interface agents. With the lack of the user’s constant supervision and control, the more adaptive an agent gets, the more unforeseeable the results caused by some actions it takes. Liability concerns are raised by indeterminate environments. So in some cases, safety mechanisms must be provided to limit the flexibility of agents and protect against all possibly unforeseen results.
Adaptivity is regarded as the key characteristic of intelligent agents, but it comes with the shadow tag of unpredictability. As the adaptive learning nature of an agent is a function of its design, it is possible for the agent to go astray from its original skeleton, especially if it is used over a long time. Hence, a balance must be struck between the limitation to be imposed in the interests of security and the flexibility that is necessary in order to operate successfully for intelligent agents.
Security has been one of the main technical obstacles for developing applications in open, distributed and heterogeneous environments, such as the Internet. Achieving security is fundamental for the successful deployment of multi-agent systems, especially in the information retrieval area. The MAS paradigm can be of interest for the security community because of the symmetry of security concerns: both information sources on the Internet and agents are subject to unwanted attacks and require appropriate protection mechanisms. On the one hand, information sources must protect themselves against malicious information agents, which visit them with some form of unauthorized permission and illegally acquire relevant information. On the other hand, information agents are vulnerable to attacks while they are in transit between two information sources and while executing in potentially malicious sites.
One possible solution to the security problems is to build a security classification and the certification of both agents and information sources by reference to a particular class of security standards. For example, an agent must be given the user’s identification certificate to fulfil certain activities on information sources. Information sources also must provide a short proof of their trustworthiness for their agent computation.
Intelligent agents sometimes require some form of user model to perform their assigned functions. However, such models contain potentially sensitive information about a user’s health, religion, financial position and social contacts. The storage or inference of such information raises important privacy issues.[8] Unfortunately, intelligent agents may magnify privacy concerns in view of their properties (autonomy, pro-activeness, social ability and reactivity).
To guarantee privacy in the application of intelligent agents, so-called ‘Privacy-Enhancing Technologies’[9] should be applied. These can be incorporated into the intelligent agents themselves. An example would be the use of biometrics, such as a fingerprint or an iris scan, which provide a unique code to identify an individual. This suggests that any agent should obtain a user’s permission before monitoring their activities, and before storing personal data.
Ultimately, users must be given control over what information about themselves is gathered, and where and how it is stored. Users are then empowered to make their own trade-off between personal privacy and improved human-computer interaction.
Software agents automatically carry out information retrieval tasks to fulfil the user’s query without any direct input or direct supervision from the user. The property of autonomy of agents leads to undesirable actions of processing IPR/copyrighted information objects[10], for example the data that an agent provides to other agents during the processing of information under a MAS environment, and the data that an agent collects for its user.
To protect the rights of IPR/copyrighted material, it is important for an agent to understand what kind of processing is allowed with IPR/copyrighted material. Such electronic material should be IPR/copyright labeled electronically in a common, internationally agreed fashion such as in the form of electronic copyright notices accompanying the material.
The same trust in a secured agent is important for information sources that receive requests by software agents for retrieving IPR/copyrighted material. To keep control, both in the technological and legal sense, over the dissemination of electronic information on information sources on the Internet and the related IPR/copyrights issues, the evaluation and certification of a secured agent need to execute in conformity with an internationally agreed scheme.
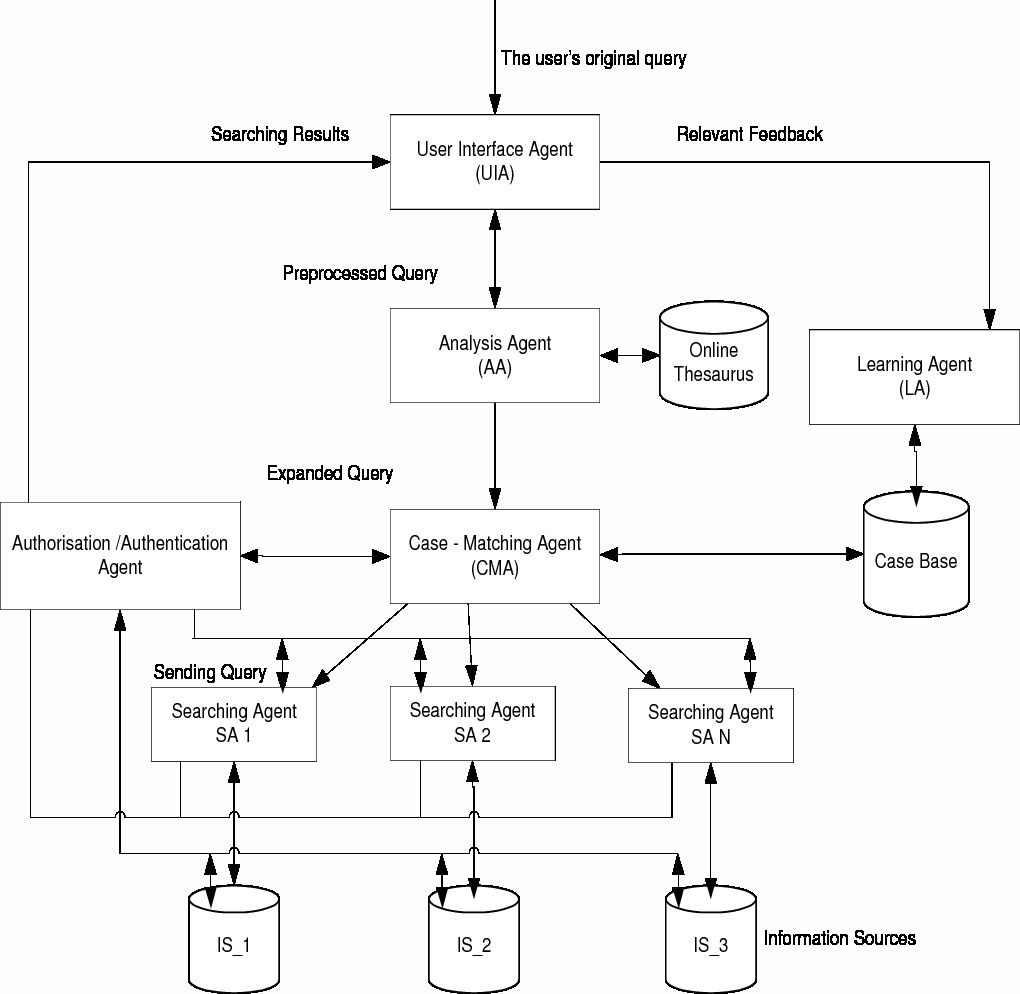
Figure 1: The security framework for IISS system
Figure 1: The security framework for IISS system
Some studies on software agents and IPR/copyright and privacy have been investigating the safeguarding of IPR/copyright and privacy in a network environment with software agents. A group of privacy enhancing technology (PET) and the use of trusted third parties (TTP) may help to counter a number of the legal issues described above.
The multi-agent system (MAS) paradigm seems to be a promising technology for developing applications in open, distributed and heterogeneous environments, such as the Internet. Many application areas, such as information retrieval can benefit from the application of the MAS technology. However, a wider diffusion of MAS on information retrieval is currently limited by the lack of a comprehensive security framework that can address the legal concerns arising in agent-based information retrieval on the Internet. This section describes an MAS environment, called IISS, an agent–based intelligent information selection system for distributed information sources that offers a security framework aimed at protecting both information sources on the Internet and agents against reciprocal malicious behavior.
To achieve security, the IISS security framework supports flexible security policies to govern the interaction of agents both with other agents and with the available information sources on the Internet.
Figure 1 is the security framework that makes IISS suitable to build and support secure application in the Internet. In IISS, the unique identities of agents and information sources are associated with X.509 certificates that bind a physical identity to a cryptographic public key pair in a secure way.[11] In addition, we associate the user with specific roles. A role is a collection of rights and duties associated with a particular position within an organization that can be adopted by a principle.[12]
During the process of information retrieval, each searching agent (SA) carries a set of exclusive credentials given by their user as part of its state. Credentials bind agents to the users and are used as proofs that agents behave according to the intentions of their users and are correctly delegated by their users to execute on their behalf. Credentials define the liability of the agents for the behavior of implemented code.
Firstly, the User Interface Agent (UIA) interacts with the user by receiving user queries and the user’s credential whose content is determined by his/her special role. Sometimes, it makes some simple preprocessing work of the user’s initial query such as removing words that are too frequent according to a stoplist and normalizing the words in the query, when necessary.
The Analysis Agent (AA) accepts the preprocessed query from UIA and takes the user’s original query terms as representative of the concepts in which the user is interested. It automatically expands the terms with a Naive Bayes classifier using a class hierarchy with a set of labeled documents in the online thesaurus, and adds other terms related to the same concepts to enrich the representation of the user’s query.
To guarantee the privacy of the user, the expanded query will come back to the UIA and get further confirmation from the user to avoid potentially sensitive information about the user being used in the process of information retrieval.
The Case–Matching Agent (CMA) carries out the selection process on distributed information sources and is underpinned by case-based reasoning. The information on “good” information sources deemed relevant by the CMA is transferred to the Searching Agent (SA) to seek for the associated information sources, and at the same time the CMA gives Authorization/Authentication Agent (AAA) the user’s credential obtained by UIA.
The Authorization/Authentication Agent (AAA) is in charge of supporting authorization, authentication and credential management. It has duplicate missions: one is to authenticate users, searching agents and information sources; the other is to permit agents access to information sources on the Internet.
When the Searching Agent (SA) is launched, the AAA is asked to supply the user’s credentials. A unique identifier and code are digitally signed by the AAA so that the computed agent credential cannot be misused on other illegal agents. When the SA is loaded to be executed at information sources, its credentials are verified in terms of authenticity. Once authenticated, agents are authorized to interact with the information source on the basis of the current security policy and pass back to the user only the information that the user is interested in.
The AAA can protect the SA from moving in an untrusted information source by using authenticated channels. Before being transferred from the current information source to the destination information source, the SA asks the AAA to validate the authenticity of the destination information source.
The Learning Agent (LA) is responsible for keeping track of a user’s relevant feedback via the User Interface Agent (UIA). By considering such feedback and using the statistical data stored in the case base, the LA can apply a reinforcement learning algorithm to adjust the values of confidence factors of matching cases in the case base and then restore the change into the case base.
IISS addresses, as a distinctive feature, some important legal issues that emerge in the context of real IR application running on the Internet: it provides a security framework for information sources and agents while both migrating over an insecure network environment.
Intelligent agents have become important and convenient instruments that assist people to search and retrieve information from large, and distributed information sources on the Internet. In general, agents are used to automate simple information processing tasks involved in searching, filtering, organizing and retrieving information. The exploitation of agent-based information retrieval applications also offers several peculiar advantages, such as adaptability, scalability, and flexibility.
However, the rise of intelligent agents increases some legal concerns such as liability, security, privacy and IPR/copyright protection. Making agents a viable technology involves more than just technical prowess. Legal standards must remain appropriate to the design of agent-based systems.
The security consideration has been taken into account in the development of the IISS framework that supports the protection of both information sources on the Internet and agents as a distinctive feature. Future work will be devoted to improve IISS facilities and to extend the IISS security framework in order to deal with open issues, such as IPR/copyrighted material on information sources on the Internet.
Authors would like to thank Mrs. Anne Fuller for her proof reading of the paper, which has been very helpful in improving the quality of this paper.
Borking, J. J. et al., Intelligent Software Agents and Privacy. The Hague: Registratiekamer, 1999.
Decker, K., Sycara, K., and Williamson, M., 'Middle-Agents for the Internet'. In Proceeding of 15th IJCAI, pages 578-583, Nagoya, Japan, August 1997.
Etzioni, O. and Weld, D. S., 'Intelligent Agents on the Internet - Fact, Fiction, and Forecast'. In IEEE Expert - Intelligent Internet Services, No. 4, page 44-49, August 1995.
Etzioni, O. and Weld, D.S,. 'A Softbot-Based Interface to the Internet'. In Communications of the ACM, 37(7), page 72-76, July 1994.
Heckman, C. and Wobbrock, J.O., 'Liability for Autonomous Agent Design'. In Autonomous Agents and Multi-Agent Systems. Kluwer Academic Publishers, pages 87-103, 1999.
Haverkamp, D. S. and Gauch, S., 'Intelligent information agents: review and challenges for distributed information sources'. In Journal of the American Society for Information Science, 49 (4), pages 304-311, 1998.
Luiijf, Cf. H. A. M. and Verhaar, P. J. A., Software Agents and IPR/copyright, The Hague: TNO-FEL 1998
Lupu E., and Sloman M., 'A Policy Based Role Object Model'. In Proceedings of EDOC’97, IEEE, October 1997.
Muller, E. M., 'An Intelligent Multi-Agent Architecture for Information Retrieval from the Internet'. In http: // citeseer.nj.nec.com/ cachedpage/94069/1
Menezes, A., et al., Handbook of Applied Cryptography. CRC Press, 1996.
Rossum, H. van, et al., 'Privacy-enhancing technologies: path to anonymity'. Volumes 1 and 2, Sdu, August 1995.
[*] School of Information Technology & Computer Science, University of Wollongong, Wollongong, NSW 2522, Australia. hy92,minjie@uow.edu.au
[1] Etzioni, O. and Weld, D.S., ‘Intelligent Agents on the Internet – Fact, Fiction, and Forecast’, IEEE Expert – Intelligent Internet Services, no. 4, August 1995, pp 44-49.
[2] Heckman, C. and Wobbrock, J.O., ‘Liability for Autonomous Agent Design’. In Autonomous Agents and Multi-Agent Systems, Kluwer Academic Publishers, 1999, pp 87-103.
[3] Etzioni, O. and Weld, D.S., ‘A Softbot-Based Interface to the Internet’, Communications of the ACM, vol. 37, no. 7, July 1994, pp 72-76.
[4] Haverkamp, D.S. and Gauch, S., ‘Intelligent information agents: review and challenges for distributed information sources’, Journal of the American Society for Information Science, vol. 49, no. 4, 1998, pp 304-311.
[5] Decker, K., Sycara, K. and Williamson, M., ‘Middle-Agents for the Internet’. In Proceedings of 15th IJCAI, Nagoya, Japan, August 1997, pp 578-583.
[6] Muller, E.M., ‘An Intelligent Multi-Agent Architecture for Information Retrieval from the Internet’, http://citeseer.nj.nec.com/cachedpage/94069/1.
[7] Heckman and Wobbrock, supra n.2.
[8] Borking, J.J. et al., Intelligent Software Agents and Privacy, The Hague: Reigstratiekamer, 1999.
[9] Rossum, H. van et al., ‘Privacy-enhancing technologies: path to anonymity’, vols. 1 and 2, SDU, August, 1995.
[10] Luiijf, Cf. H.A.M. and Verhaar, P.J.A., Software Agents and IPR/copyright, The Hague: TNO-FEL, 1998.
[11] Menezes, A. et al., Handbook of Applied Cryptography, CRC Press, 1996.
[12] Lupu, E. and Sloman, M., ‘A Policy Based Role Object Model’. In Proceedings of EDOC ’97, IEEE, October, 1997.
AustLII:
Copyright Policy
|
Disclaimers
|
Privacy Policy
|
Feedback
URL: http://www.austlii.edu.au/au/journals/JlLawInfoSci/2001/5.html